oracle之正则表达式的使用
CreateTime--2017年11月23日14:20:29
Author:Marydon
1.参考链接
2.基本用法
ORACLE中的支持正则表达式的函数主要有下面四个:
1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与INSTR的功能相似3,REGEXP_SUBSTR :与SUBSTR的功能相似4,REGEXP_REPLACE :与REPLACE的功能相似它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。'.' 匹配除换行符之外的任何单字符。'?' 匹配前面的子表达式零次或一次。'+' 匹配前面的子表达式一次或多次。'*' 匹配前面的子表达式零次或多次。'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。'( )' 标记一个子表达式的开始和结束位置。'[]' 标记一个中括号表达式。'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。字符簇: [[:alpha:]] 任何字母。[[:digit:]] 任何数字。[[:alnum:]] 任何字母和数字。[[:space:]] 任何白字符。[[:upper:]] 任何大写字母。[[:lower:]] 任何小写字母。[[:punct:]] 任何标点符号。[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。3.常用的正则表达式
用户名:/^[a-z0-9_-]{3,16}$/
密码:/^[a-z0-9_-]{6,18}$/
十六进制值:/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
电子邮箱:/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
URL:/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
IP 地址:/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
HTML 标签:/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
Unicode编码中的汉字范围:/^[u4e00-u9fa5],{0,}$/
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始匹配中国大陆邮政编码:[1-9]\d{5}(?!\d)
评注:中国大陆邮政编码为6位数字匹配身份证:\d{15}|\d{18}
评注:中国大陆的身份证为15位或18位匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用匹配特定数字:
^[1-9]\d*$ //匹配正整数^-[1-9]\d*$ //匹配负整数^-?[1-9]\d*$ //匹配整数^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)评注:处理大量数据时有用,具体应用时注意修正匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串^[a-z]+$ //匹配由26个英文字母的小写组成的字符串^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串4.实际应用
案例一:查询性别字段为不是纯数字的记录
--方式一SELECT SEX FROM VIRTUAL_CARD WHERE NOT REGEXP_LIKE(SEX,'^[0-9]+$') OR SEX IS NULL;
执行结果:

点评:使用'^[0-9]+$'匹配的值必须全是正整数或0,值为空的需要单独判断
--方式二SELECT SEX FROM VIRTUAL_CARD WHERE NOT REGEXP_LIKE(SEX,'^[[:digit:]]+$');
执行结果:
点评:使用'^[[:digit:]]+$'匹配的值必须全是正整数或0,值为空的需要单独判断
--方式三SELECT SEX FROM VIRTUAL_CARD WHERE REGEXP_LIKE(SEX,'^[a-zA-Z]+$');
执行结果:
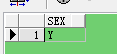
点评:
使用'^[a-zA-Z]+$'匹配的值必须全是字母,值为空的需要单独判断;
这种方式,中文不会被筛选出来;
另外,匹配字母a-Z的表达式,正确用法为[a-zA-Z],[a-Z]是错误用法。
--方式四SELECT SEX FROM VIRTUAL_CARD WHERE REGEXP_LIKE(SEX,'^[[:alpha:]]+$');
执行结果:
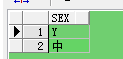
点评:
使用'^[[:alpha:]]+$'匹配的值必须全是字母,值为空的需要单独判断;
该表达式会将全是中文的记录筛选出来。
--方式五SELECT SEX FROM VIRTUAL_CARD WHERE REGEXP_LIKE(SEX,'^[^[:digit:]]+$');
执行结果:
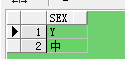
点评:
使用'^[^[:digit:]]+$',表示:值里面不包含任何数字,匹配的值不包含数字的将会被筛选出来,
换句话说,只要字段值里面有一个数字,则该条记录就不会被筛选出来。
相关推荐: